
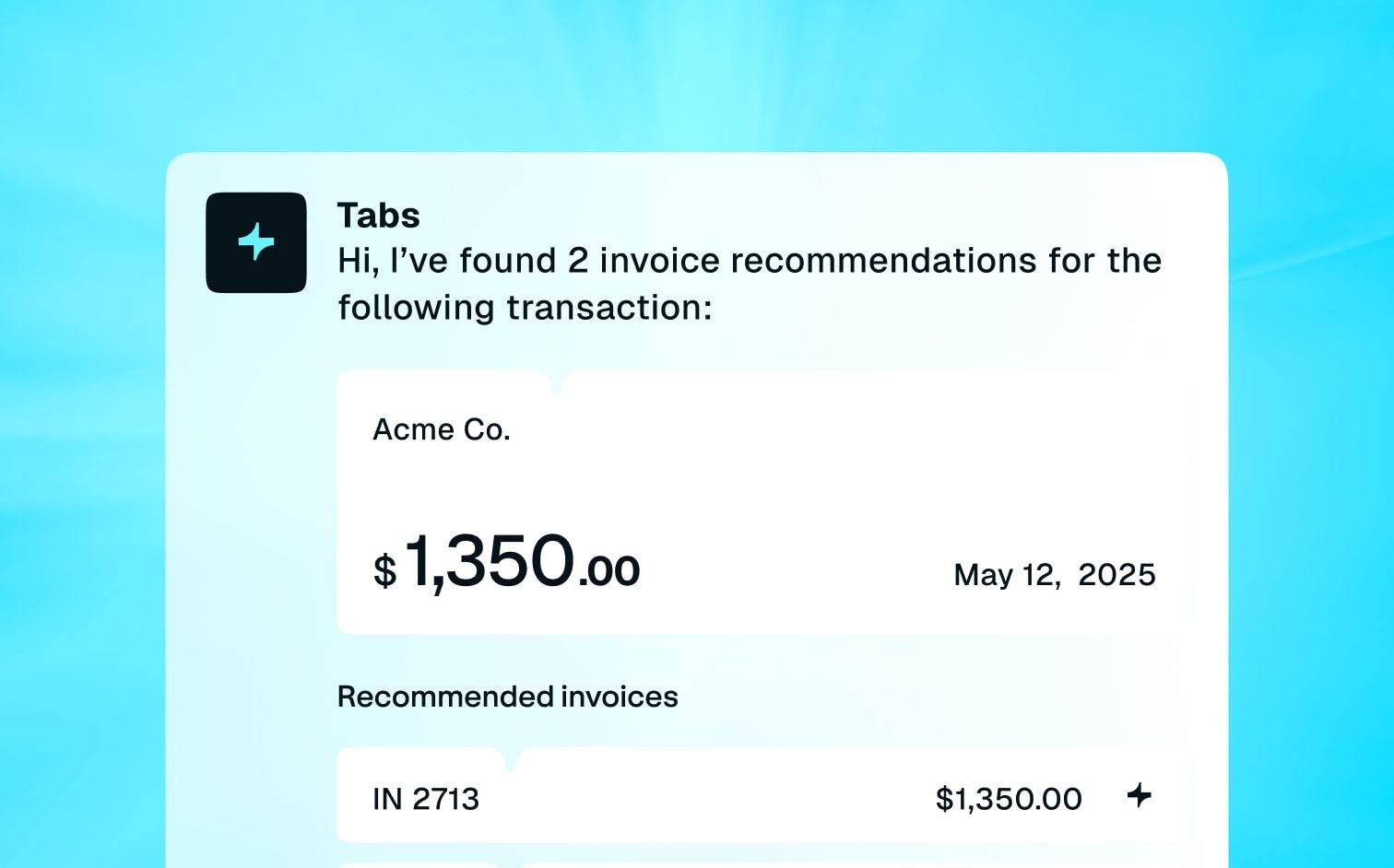
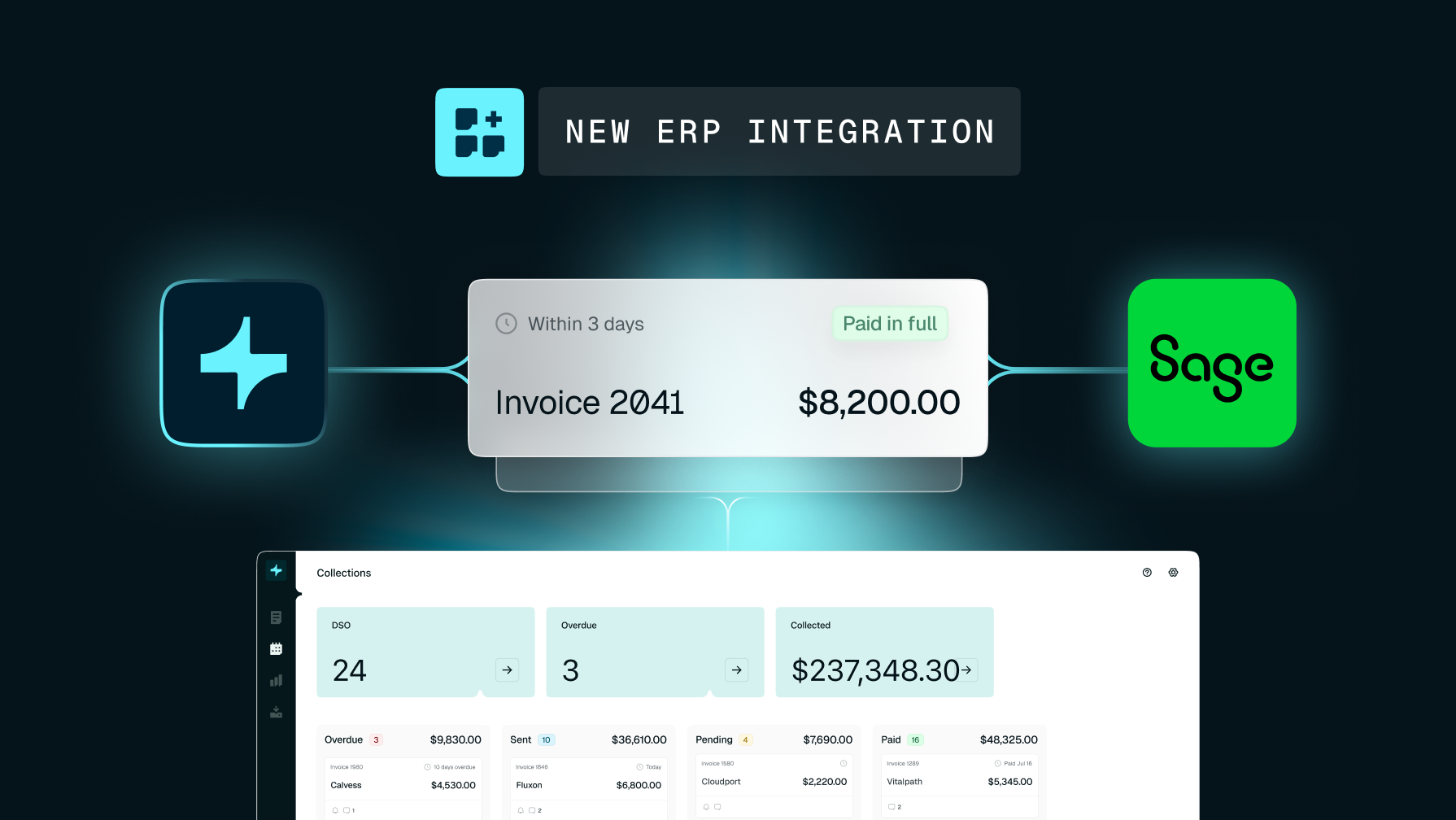


Usage-based billing breaks down when systems can’t keep up with scale.
As companies scale and product usage grows, so does the complexity of their usage data. Finance teams are often left reconciling CSV uploads, waiting for batch jobs, or scrambling with ad-hoc ingestion that wasn’t designed for real-time billing or auditability.
Tabs was built to eliminate that friction.
Today, we’re sharing Tabs' brand-new usage engine that powers billing at scale, ingesting over 100,000 events per second and transforming raw usage into accurate, auditable invoices and real-time insights. This is enterprise-grade infrastructure designed to balance high-throughput ingestion across all customers with built-in safeguards, including per-customer limits of 10,000 events per minute. The result is a system that allows for seamless event ingestion so finance teams can capture customer activity in real time and track consumption across commitments, burndowns, and remaining balances.
In this blog post, we’ll break down the architecture behind our new real-time usage engine and explain how it powers scalable, usage-based billing without the manual and cross-functional overhead.
What does this unlock for finance and engineering teams
With the new usage engine, engineering teams can hand off usage data to finance through a simple, reliable system, while accounting teams gain clear, granular visibility into customer usage and billing. This seamless, end-to-end operational autonomy helps usage-based businesses close faster and adapt to contract updates with confidence as they scale.
Using Tabs for usage-based billing, businesses can:
- Accelerate billing and close cycles by eliminating the typical manual effort of reconciling usage data, pricing logic, and contract terms
- Support pricing and contract changes more flexibly by regenerating invoices automatically as either evolve, without extensive engineering involvement
- Reduce operational burden across your finance and engineering teams with backend infrastructure designed for the lowest friction when it comes to real-time usage ingestion and aggregation
Finance gets:
- Full control over pricing and billing schedules
- On-demand invoice regeneration
- Real-time usage visibility
- Independence from engineering for billing operations
Engineering gets:
- A straightforward HTTP API with idempotency and built-in rate limiting
- No aggregation pipelines to maintain
- No invoice calculation logic to version control
Three Simple Pieces, One Unified System
Our real-time usage engine is intentionally straightforward: a fast ingestion API (in beta) takes in customers’ usage events, which are then validated, aggregated, and surfaced within minutes so finance can track consumption and regenerate invoices without waiting on engineering or end-of-period batch jobs.
Under the hood, Tabs uses proven streaming and analytics technology to process and surface usage data reliably as it arrives. This architecture is purpose-built to scale cleanly across customers while preserving the accuracy, consistency, and auditability finance teams need to trust every invoice and close with confidence.
1. The Usage API: Built to Stay Out of Your Way
We designed the Usage API to be both high-throughput and low-friction. It handles a ton of simultaneous traffic without needing a massive fleet of servers, so it keeps up even when usage spikes. To keep things stable at that scale, we enforce rate limits with Redis as the shared source of truth. And we add a simple dual-cache layer on top: each API node keeps a small local cache for near-instant checks, while Redis stays in sync behind the scenes to make sure limits hold across the whole system.
Events are intentionally minimal. We only ask for the essentials: customer ID, event type, timestamp, value, and a unique idempotency key. Everything else that tends to slow teams down, such as pricing tiers, billing cycles, revenue splits, contract overrides, lives downstream in configuration. Engineering can send raw usage data and move on, while finance can adjust the model over time without rewriting code or triggering new deployments. Read the API docs here.
The Result: Flexible Invoice Regeneration
With aggregated event tables, the billing engine can read to regenerate invoices as needed. That means if pricing changes mid-cycle, finance updates the contract in Tabs and the system applies it retroactively to unbilled periods—no engineering loop needed.
2. Kafka + Clickhouse: Streaming That Stays Reliable
Once events land, Kafka becomes the backbone of the pipeline. Kafka is a system that acts like a central mailroom for data, letting different systems send, receive, and process information in real time without needing to talk to each other directly. Think of it as a durable, ordered highway for usage data. Kafka connects directly into ClickHouse, our dedicated usage database, so analytics stay close to real time. As events stream in, product and finance teams can see usage roll up immediately and eliminate any last-minute batch jobs.
3. Real-Time Aggregation with ClickHouse
ClickHouse is the piece that makes usage feel live in Tabs. We use materialized views to roll events up by customer, event type, and day as they arrive. No batch jobs for finance—your billable invoices stay current within minutes.
ClickPipes connects Kafka and Postgres, our main database, directly into ClickHouse. Kafka events land with managed consumption and recovery, and Postgres changes sync in real time via CDC (change data capture pipeline tracking all database changes). That means usage, customers, contracts, and pricing rules are all in one place, so we can join live usage with product and finance data for instant reporting.
The Result: Streamlined Event Tables
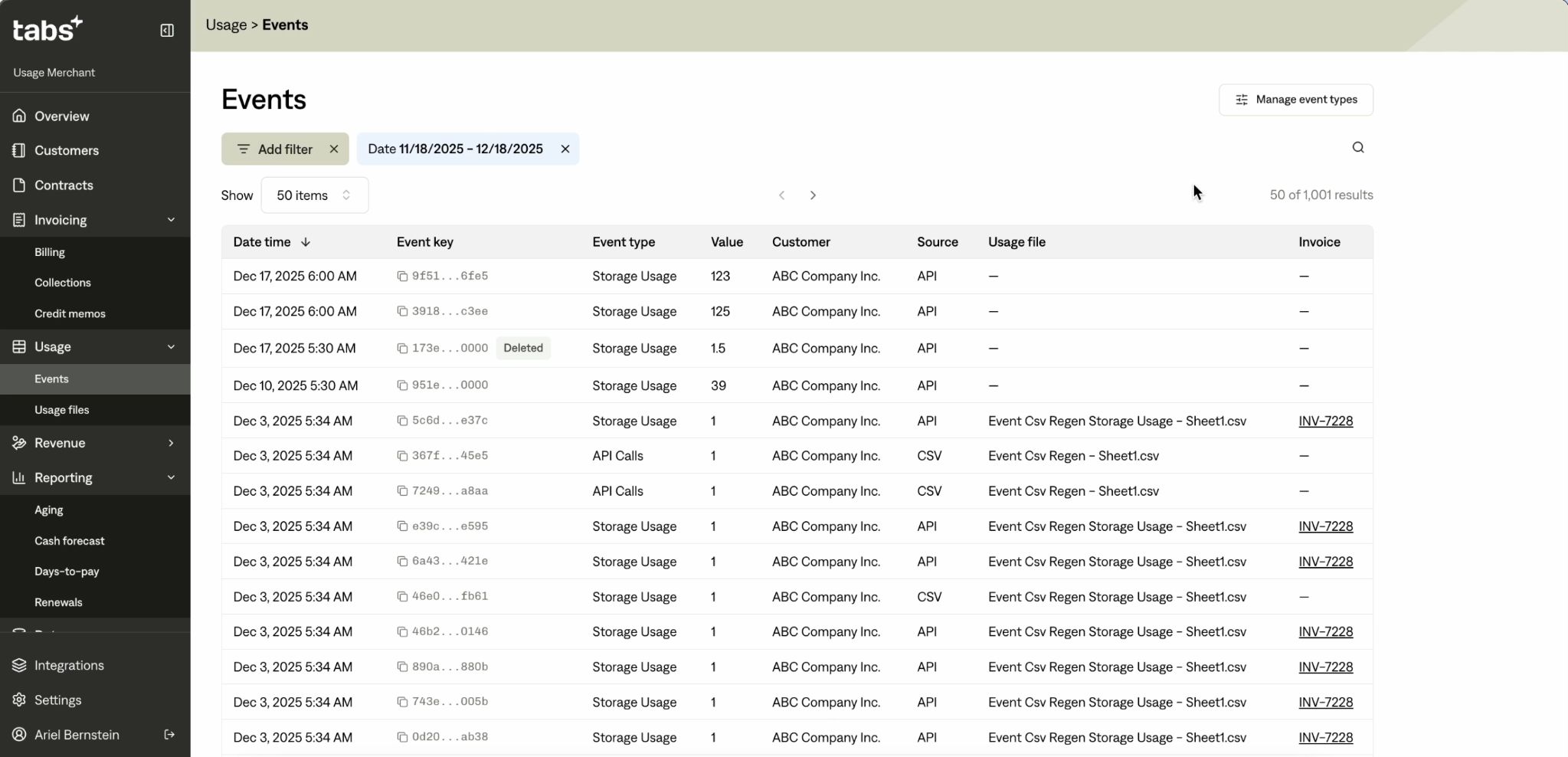
With this critical infrastructure in place, you now have cleaner visibility into ingested usage events and their corresponding invoices. At a more granular level, this means Tabs users can:
- See a full list of ingested events and their source (API, CSV, Invoice)
- See which specific invoice an event is linked to
- Filter/group events by invoice, customer, event type, etc.
High volume infrastructure so you can bill faster
Usage-based billing doesn’t fail because the model is flawed; it fails when the infrastructure behind it can’t scale nor connect the full revenue workflow. Tabs’ real-time usage engine unifies contract processing, usage ingestion, and billing in a single platform, giving finance teams the accuracy, visibility, and control they need to close with confidence, while freeing engineering from maintaining fragile pipelines and billing logic.
Want to learn how this works for your business? Chat with our team to learn how you can bill for usage at scale with Tabs.
If you’re a Tabs customer and your company is transitioning to usage-based pricing, reach out to your customer success manager to learn how Tabs can support that transition.